
This article provides a detailed description of all the features and options associated with the Classifier Settings
As described in more detail in Classifier Overview, Reveal automatically creates a Classifier when you create an AI Tag. Once the Classifier has been created, you can review and modify the Classifier settings within the Supervised Learning menu option. A description of each of the available settings can be found in this article.
Edit Classifier
To access the Classifier settings, click the gear icon in the upper right-hand corner of the classifier card. To return to the Classifiers screen from there, click on the "Classifiers" breadcrumb at the upper left of the screen.
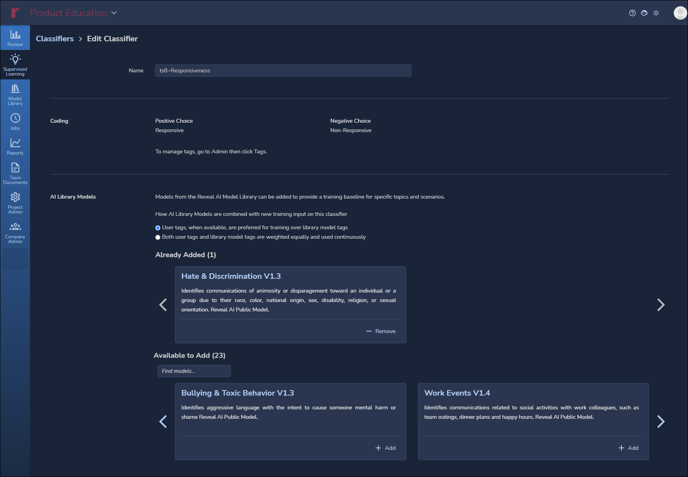
- Name - The name of the Classifier. You can edit the name here within the Classifier settings.
- Coding - Shows the choices available for the associated AI Tag.
- AI Library Models - Shows saved models available to add to this classifier (by clicking +Add on an Available to Add Library Model card), and those already added.
- How AI Library Models are combined with new training input on this classifier:
- User tags, where available, are preferred for training over library model tags (the default). This option allows Reveal to utilize tagged documents to influence the calculation of the predictive scores instead of the added AI Model from the AI Model Library.
- Both user tags and library model tags are weighted equally and used continuously. This option allows Reveal to equally use both tagged documents, and any added AI Model from the library, to influence the calculation of the predictive scores.
- How AI Library Models are combined with new training input on this classifier:
Note: When you add or remove an AI Model from the library to your Classifier, you must select Run Full Process to ensure the addition or removal of the model is reflected in the Classifier training results.
- Batch Composition - This setting allows you to determine how documents are selected when creating review batches using the AI Driven Batches feature.
- Active Learning with Diverse Documents - this option selects documents across score ranges that will train the classifier in the least amount of time. The goal is to train the classifier with the least number of documents tagged by human reviewers.
- Active Learning with Diverse Documents is typically used when you're building a Classifier for the purpose of auto-coding documents for a production to a third-party.
- Active Learning with Diverse Documents - this option selects documents across score ranges that will train the classifier in the least amount of time. The goal is to train the classifier with the least number of documents tagged by human reviewers.
-
- Active Learning with High-Scoring Documents - this option select the documents with the highest predictive scores. The goal is to review the most likely responsive documents first so that you more quickly identify evidence of wrongdoing or finalize your legal strategy more quickly.
- Active Learning with High-Scoring Documents is typically used in ECA and investigations when it's important to review the most likely relevant content first.
- Active Learning with High-Scoring Documents - this option select the documents with the highest predictive scores. The goal is to review the most likely responsive documents first so that you more quickly identify evidence of wrongdoing or finalize your legal strategy more quickly.
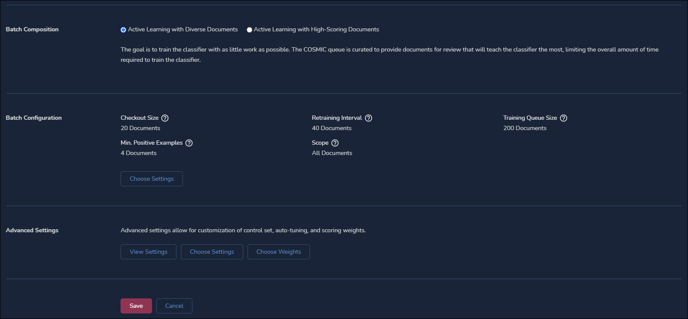
- Batch Configuration - Allows you to configure the batch size and training interval settings for the Classifier and its associated review batches.
.png?quality=high&width=688&height=328&name=35%20-%2003%20-%20Edit%20Classifier%2002%20(Batch%20Configuration).png)
- Checkout size – The number of documents available to a reviewer to checkout for review for a specific batch.
- Retraining Interval – The number of documents that need to be coded in order for the next training round to kickoff for the specific Classifier.
- Training Queue Size – The number of documents made available for batching at the end of each round of training.
- Min. Positive Examples – The minimum number of documents that must be coded using the AI Tag's positive choice before the first round of training can start.
- Advanced Settings - The Advanced Settings section provides you with the ability to view and modify the weights associated with each of the features used to calculate predictive scores for each document. You can enable and disable certain advanced settings.
- Choose Settings - This option allows you to view and modify the following:
- Autotune - Enable or Disable classifier autotuning. When this feature is set to "Enable", Reveal will automatically select the appropriate weighting for each feature that will influence the calculation of predictive scores for the given Classifier. A feature is either a specific keyword, phrase, or metadata field value.
- Autotune Threshold – Set the maximum number of documents in which autotuning should be used to calculate predictive scores after each training round. Once the total number of tagged documents exceeds this value, the system will continue to use the last calculated set of feature weights to calculate predictive scores.
- Reports - Enable Run Feature and Score Reports - This setting gives you the option of generating the Feature and Score Reports. If you're using the predictive scores to simply prioritize review, then you may not need to generate these reports since they're used to evaluate the Classifier training progress. Generating these reports will impact the performance of the training process.
-1.png?quality=high&width=500&height=197&name=35%20-%2007%20-%20Edit%20Classifier%20Details%2004%20(Advanced)-1.png)
- Choose Weights - This feature allows you to manually adjust the weights of each feature including: keywords, phrases, metadata, entities, etc.
- View Settings – Displays all current features and their associated weights.
Last Edited 6/28/2024