
This article provides both visual and written instructions for indexing document data for a project.
Non-Audio Video Tutorial
After importing documents has completed, the data will need to be indexed. An index at the most basic level locates words imported into the project to enable searching and highlighting of search hits; however, Reveal runs additional processes during this time (i.e., conversion into html, text extraction and color detection).
With the deployment of Reveal 2024.5, bulk updates and incremental analytics indexing will run in parallel without queuing or interrupting running processes. This will facilitate continuous improvement of Reveal without impact on workflow.
Below is a chart that indicates whether indexing is required for specific Text Sets after the corresponding event has occurred. Note that Image Labeling, like Transcription and Translation, kicks off its own indexing job for the metadata generated.
|
Text Set |
||||||||
|
Event |
HTML / Native* |
Extracted |
OCR / Loaded |
Metadata |
Translation |
Transcription |
Native View |
Spreadsheet View |
|
Data Import - DM |
Optional |
Optional |
Automated |
Automated |
N/A |
N/A |
Optional |
Optional |
|
Data Import - RM |
Optional |
Optional |
Optional |
Required |
N/A |
N/A |
Optional |
Optional |
|
Data Import - Uploader |
Optional |
Optional |
Automated |
Automated |
N/A |
N/A |
Optional |
Optional |
|
OCR |
Optional |
Optional |
Automated |
Automated |
N/A |
N/A |
Optional |
Optional |
|
Transcription |
N/A |
N/A |
N/A |
N/A |
N/A |
Automated |
Optional |
Optional |
|
Translation |
N/A |
N/A |
N/A |
N/A |
Automated |
N/A |
Optional |
Optional |
|
Color Detection |
N/A |
N/A |
N/A |
Optional |
N/A |
N/A |
Optional |
Optional |
Text Set descriptions are:
-
HTML/Native - Extracted HTML content from native files, such as web pages or other HTML-based documents.
-
Extracted - Extracted text from native files, such as Word documents, email messages, PowerPoint slides, or Excel spreadsheets.
-
ORC/Loaded - Extracted text from image files using Optical Character Recognition (OCR) or loaded text accompanying the images.
-
Metadata - Extracted information about the file’s attributes, such as author, creation date, or file format, often used for categorization and searching.
-
Transcription - Extracted text from audio or video files, representing spoken words as written content.
-
Translation - Extracted translated text from a document, converting content from one language to another while retaining the structure of the original.
-
Native View - Extracted representation of a document in its original file format (e.g., Word, PDF, Excel) for viewing without conversion or modification.
-
Spreadsheet View - Extracted data from native spreadsheets (e.g., Excel), displayed in a grid format, allowing users to view and interact with rows and columns.
* Bulk Actions Index Button: This Grid button can be used to quickly index native and extracted text from the front end. The record’s Text Set(s) will only be indexed if it has not previously been indexed.
** OCR can be sent to the OCR/Loaded text set or new text sets can be created to store the OCR.
For Processing's "Review Append" exports (that is, native and other material ingested through Reveal Processing and not Review Manager), only the Document_Metadata & OCR loaded will get indexed automatically through the API.
NOTE on reindexing metadata: When creating a new custom field and Updating Data to that newly created field (overlaying in RM), Document_Metadata must be reindexed to make the new content visible within the Grid View.
Items not indexed initially (other than Document Metadata, which must be indexed to populate the Grid) may be indexed from within the Reveal application. See Additional Indexing from the Grid below.
Initial Indexing and Index Management
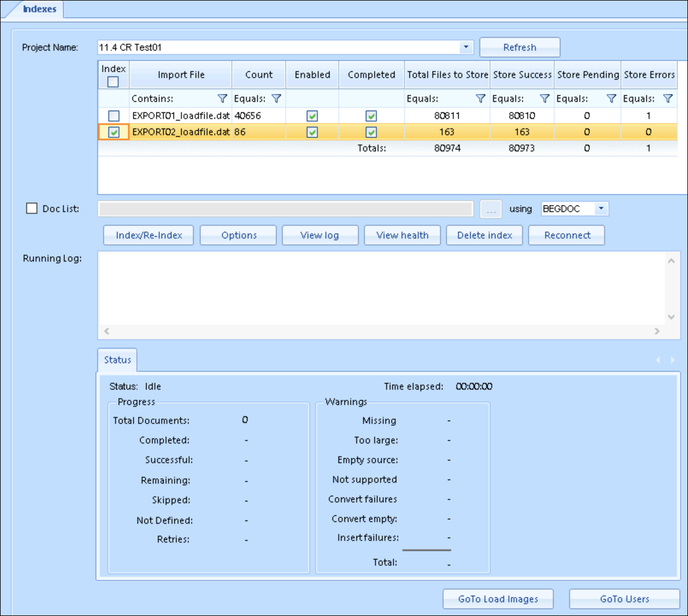
- Connect to a system running Review Manager and log in as an Administrator.
- Open the Create pane.
- Choose Indexes.
-
In the Project Name field, use the dropdown menu to select your project.
-
In the Index table select the set of loaded data identified in the Import File column to be indexed. You may use Contains or Equals filters in the column headings to refine the list for selection.
-
To alert teams and/or users upon completion of an indexing job,
-
select Options button and
-
go to the Notifications tab to choose the appropriate recipients.
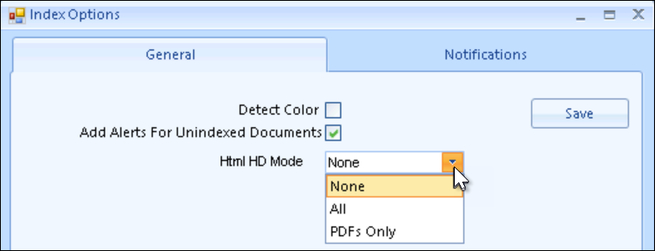 The General tab offers settings to Detect Color, Add Alerts For Unindexed Documents and selection of Html HD Mode to be used (None, All, or PDFs Only). HTML HD Mode allows for a higher definition rendering of the HTML view for documents that aren't indexed as text. This may result in better fidelity to the original native document. This will result in a slower processing time and larger index size. NOTE that Detect Color must be turned on here to implement color detection during indexing; otherwise this process must be done manually.
The General tab offers settings to Detect Color, Add Alerts For Unindexed Documents and selection of Html HD Mode to be used (None, All, or PDFs Only). HTML HD Mode allows for a higher definition rendering of the HTML view for documents that aren't indexed as text. This may result in better fidelity to the original native document. This will result in a slower processing time and larger index size. NOTE that Detect Color must be turned on here to implement color detection during indexing; otherwise this process must be done manually.
-
- Choose the Index/Re-Index button located in the middle of the window beneath the Index table.
- Select the Document Text Sets you wish to index. By default the Native/HTML, Extracted, and OCR/Loaded text sets are present, but additional text sets may have been added to the current project.
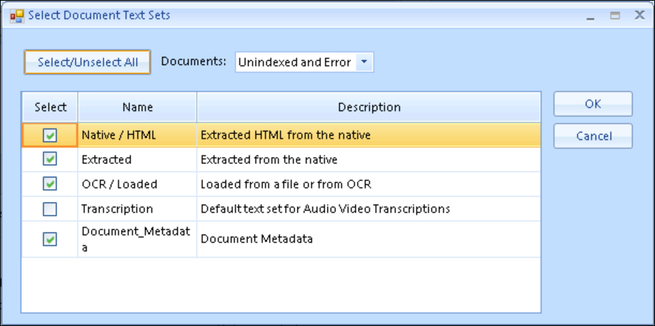
- The Text Set choices will determine the order which the sets will be indexed.
- OCR/Loaded will be indexed first, if present, then the Extracted Text will be indexed, followed by the Native/HTML view.
NOTE: The OCR/Loaded or Extracted Text Sets (preferably both) must be indexed to enable keyword search. Indexing the Native/HTML Text Set is necessary for document viewer rendering, but does not provide search capabilities.
-
This is done to get data into the project as quickly as possible to make the documents searchable.
- OCR/Loaded will be indexed first, if present, then the Extracted Text will be indexed, followed by the Native/HTML view.
-
- As soon as a Text Set completes indexing, the project will become searchable.
- If Document Metadata is overlaid or updated, that portion alone may be selected and indexed as a text set without having to reindex all content in the dataset.
- When indexing is complete the documents may be viewed in the Native / HTML viewer in the Document Review screen and Document Metadata will appear in the Review Grid.
- To examine the indexing log for the current or previous jobs in the project, click View Log.
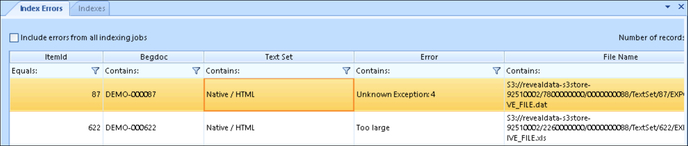
- To get information about the health of indexes, click View Health. The report window will provide details about the index, including the text sets indexed and their counts.
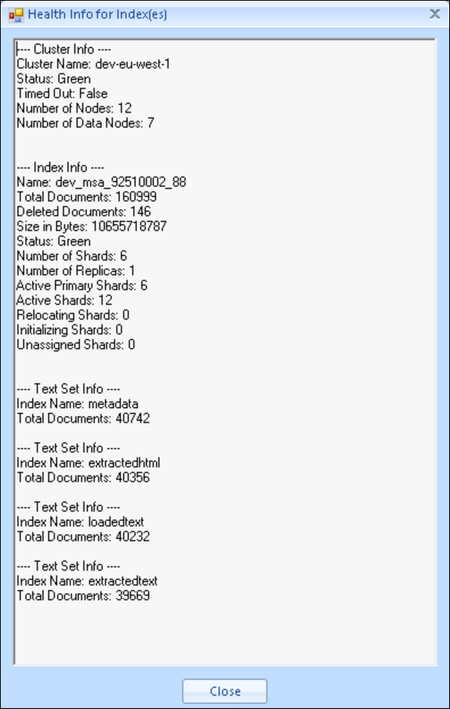
For performance reasons there is a hard limit of 16MB expanded text size for indexing documents in the Native / HTML text set. While settings in Review Manager may be set to indicate a larger limit, any document exceeding the 16MB limit will not index and an error will appear in the indexing log. We strongly recommend contacting Reveal Support if encountering this limitation.
Note: The native and text file sizes differ from the expanded file sizes. The expanded file size is the size of the text set created.
Specific documents can be targeted using the Doc List field to specify a List file containing the identified document numbering field (BEGDOC by default). Users can choose between Unindexed and Errors, Non-Error, and All Documents.
Users can choose to change the priority of a specific indexing jobs. The priority of a job is relative, so if a user chooses to make all indexing jobs High priority, the net effect is that all jobs are the same priority and, therefore, there is no high priority.
Progress
-
Total Documents – All Documents to be attempted to be indexed in the current job. This is scoped by the data sets or docid list that is selected.
-
Completed – Documents that were attempted to be indexed in the current job.
Note: The “Successful” count + Warnings “Total” count = The “Completed” count.
-
Successful – Documents that were successfully indexed in the current job.
-
Remaining – Documents to be attempted to be indexed in the current job.
-
Skipped – When running an “Unindexed and Error” or “Non-Error” index job unindexable files will get skipped (e.g. empty source files). Skipped Documents are included within the Successful count.
-
Not Defined – The path to the OCR or native is missing.
-
Retries – Indexing process was re-attempted on a document. Typically happens if an attempt to index a document times out.
Warnings
-
Missing – Native was not found.
-
Too Large - File is larger than the size limits set within the Text Set settings. See Creating Document Text Sets in the Review Manager Administration Guide for details.
-
Empty Source - File is empty, so it has no content to extract or convert.
-
Not Supported - Error when extracting text and creating html from an unsupported file type.
-
Convert Failures - Error when extracting text and creating html from the native. These are typically corrupt or encrypted files.
-
Convert Empty - Conversion of native was successful but there was no output text.
-
Insert Failures – There was a failure when attempting to add the document’s text to the Elastic Index.
Note: Convert is the process of extracting text and rendering html from the native.
If the Reveal Review Manager gets closed during an indexing job, the job continues to run. It may be useful for the user to reconnect to a currently running job, or an already completed job.
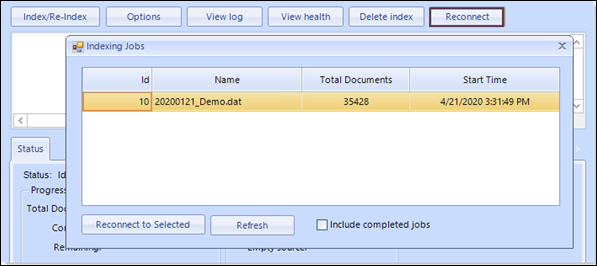
To Reconnect with an indexing job:
-
Open the Create pane and select Indexes to open.
-
Select the Reconnect button and a list of currently running jobs for the selected project will be presented.
-
Select the job to reconnect to and select the 'Reconnect to Selected' button.
-
To see jobs that have already been completed, select the 'Include completed jobs' checkbox and both running and completed jobs will be shown in the list.
-
Select the job in question and the statistics for the job will be displayed within the Status area.
-
For running jobs, their current status will be updated and displayed and the user will be able to continue to monitor the progress of the job.
Additional Indexing from the Grid
Once Document Metadata are indexed, these entries will appear in the Reveal Grid view. From there, the Index bulk action may be used to add searchable material which may have been overlaid or skipped initially.
- In Reveal’s Grid view, search or filter or directly select the documents to be indexed.
- Click Index from the Grid actions menu bar.
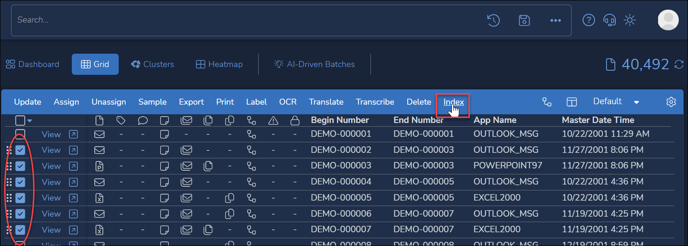
- In the Index Documents window, select the set of documents (Selected documents or All documents in results list) to Act On.
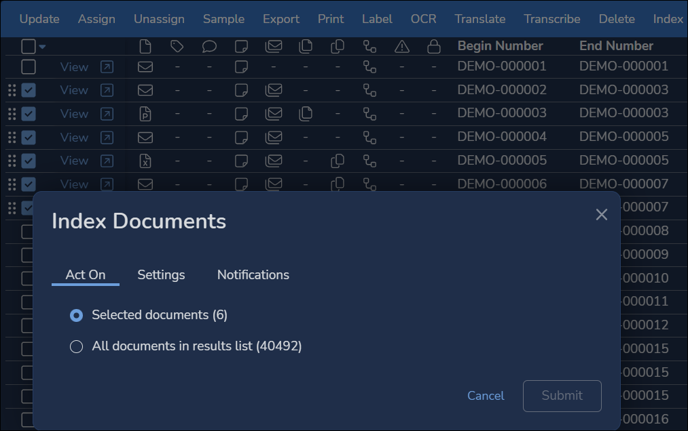
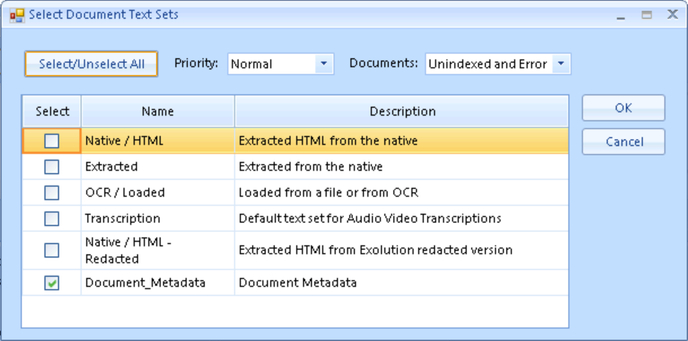
- Configure the indexing Settings:
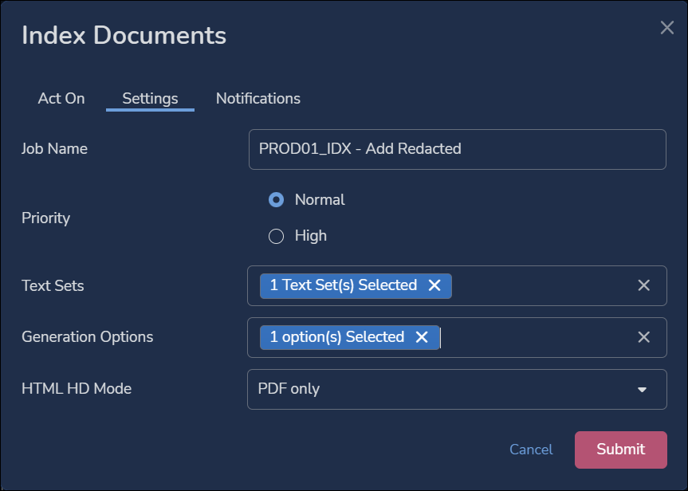
- Enter a Job Name to check and log the progress of the Job.
- Set the Priority - Normal is default, High may be selected as required.
- Choose the appropriate Text Sets for the data to be indexed.
- Select appropriate Generation Options (Select all is the default):
- Select all
- Detect color
- Add alerts for unindexed documents.
- HTML HD Mode may be set for All or PDF only; since HTML is always indexed in high definition, this setting defaults to PDF only.
- Notifications sets who should be updated about the status of the indexing job, selected Team or selected Users.
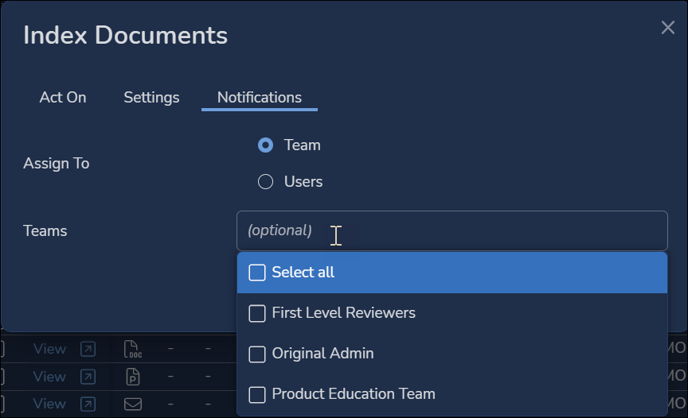
NOTE that users will automatically be notified if an index job is currently running to explain effect on delayed visibility of bulk-updates.
- Click Submit to start the indexing job. Status will be reported in the Jobs screen’s Index tab.
This Index action will only address items not already indexed. It will not overwrite an existing index for the specified text set. Overwriting or removing an existing index must be done in Review Manager.
Last Updated 6/21/2024